Hi there! I’m Shrijith Venkatrama, founder of Hexmos. Right now, I’m building LiveAPI, a tool that makes generating API docs from your code ridiculously easy.
In this hands-on tutorial, we’re going to explore the vanishing gradient problem in deep neural networks—a tricky issue that can slow down or even stop learning in early layers.
You can run the sample code in a Jupyter Notebook, see diagrams, and have those “aha!” moments as we go.
We’ll use Python with NumPy (and a touch of PyTorch later) to keep things clear and practical.
By the end, you’ll also see how the ReLU activation function can save the day!
Let’s dive in, step by step, with bite-sized code snippets and plenty of explanations then.
Setting Up Your Environment
First, let’s get our tools ready. We’ll use NumPy for calculations and Matplotlib for visualizations. Open a Jupyter Notebook and run this:
1
2
importnumpyasnpimportmatplotlib.pyplotasplt
Now, let’s define the sigmoid activation function and its derivative, since they’re central to understanding the vanishing gradient problem.
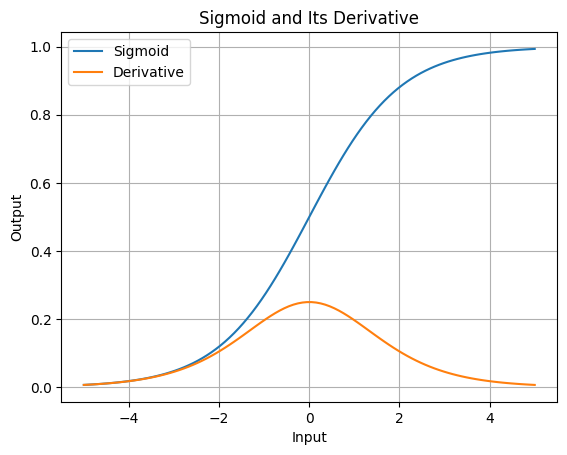
The sigmoid function squashes any input into a range between 0 and 1.
Its derivative (which we’ll use in backpropagation) is always small—its maximum value is 0.25. This tiny derivative is a big clue to why gradients vanish!
Let’s visualize sigmoid and its derivative to get a feel for them:
1
2
3
4
5
6
7
8
9
x=np.linspace(-5,5,100)plt.plot(x,sigmoid(x),label='Sigmoid')plt.plot(x,sigmoid_derivative(x),label='Derivative')plt.legend()plt.title('Sigmoid and Its Derivative')plt.xlabel('Input')plt.ylabel('Output')plt.grid(True)plt.show()
Aha Moment:
Notice how the derivative peaks at 0.25 and drops to near 0 for large positive or negative inputs. When we multiply these small values across layers, gradients can shrink fast.
Building a Tiny Neural Network
Let’s create a simple network with:
1 input neuron (value = 0.5)
2 hidden layers (1 neuron each)
1 output neuron (target = 0.8)
We’ll set all weights to 0.5 and biases to 0 for simplicity.
1
2
3
4
5
6
7
8
9
10
11
# Input and targetinput_data=np.array([[0.5]])target_output=np.array([[0.8]])# Weights and biasesweights1=np.array([[0.5]])# Input to Hidden Layer 1bias1=np.array([[0]])weights2=np.array([[0.5]])# Hidden Layer 1 to Hidden Layer 2bias2=np.array([[0]])weights3=np.array([[0.5]])# Hidden Layer 2 to Outputbias3=np.array([[0]])
Each arrow has a weight of 0.5, and each neuron uses the sigmoid function
Forward Pass—Making a Prediction
Let’s compute the output step by step. Run each line and see how the signal flows:
Aha Moment: Our prediction (≈ 0.571) is way off the target (0.8). We need to adjust the weights, but that depends on gradients. Let’s see if they’re strong enough to help!
Compute the Loss
Let’s measure how bad our prediction is using mean squared error:
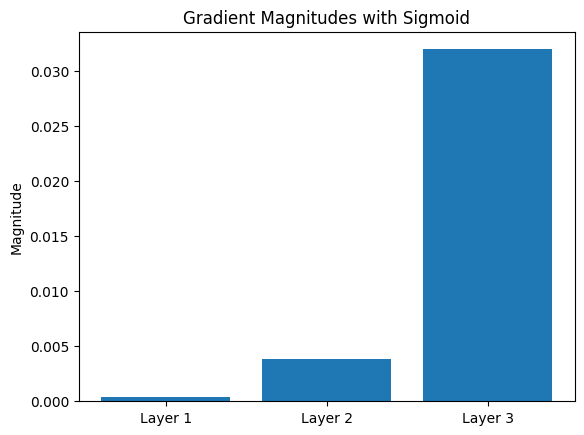
gradients=[abs(gradient_weights1[0][0]),abs(gradient_weights2[0][0]),abs(gradient_weights3[0][0])]layers=['Layer 1','Layer 2','Layer 3']plt.bar(layers,gradients)plt.title('Gradient Magnitudes with Sigmoid')plt.ylabel('Magnitude')plt.show()
Insight: The deeper we go (toward Layer 1), the tinier the gradients get. This is the vanishing gradient problem—early layers barely learn because their updates are so small!
Why Do Gradients Vanish?
Here’s the key: each gradient is multiplied by the sigmoid derivative (max 0.25). Across layers, it’s like:
Layer 3: gradient
Layer 2: gradient × <0.25
Layer 1: gradient × <0.25 × <0.25
Intuition: Imagine passing a message through a chain of people, each whispering quieter. By the time it reaches the start, it’s almost silent. That’s what’s happening to our gradients!
How ReLU Solves the Vanishing Gradient Problem
Let’s switch to ReLU (Rectified Linear Unit), defined as:
$$ReLU(x) = max(0,x)$$
with a derivative of 1 for $x>0$. This doesn’t shrink gradients! Let’s define it:
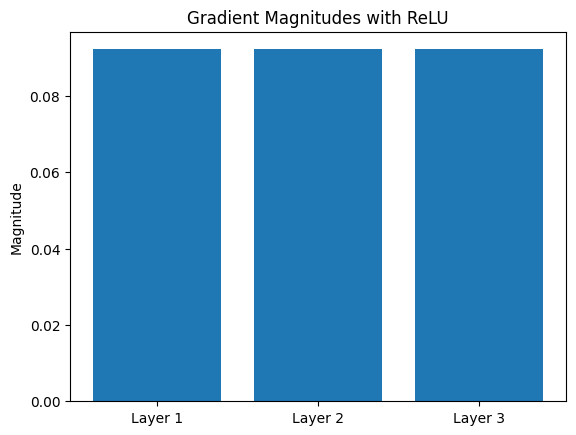
gradients_relu=[abs(gradient_weights1[0][0]),abs(gradient_weights2[0][0]),abs(gradient_weights3[0][0])]plt.bar(layers,gradients_relu)plt.title('Gradient Magnitudes with ReLU')plt.ylabel('Magnitude')plt.show()
Insight: ReLU’s derivative of 1 (for positive inputs) keeps gradients strong, so early layers can learn just as well as later ones. No vanishing here!
Bonus: Trying it With PyTorch
Let’s quickly see this with PyTorch for a modern twist. Install PyTorch if you haven’t (pip install torch), then run: